
Numerical Library Example
Please view the source code for this example. The example serves several purposes:
-
demonstrate use of the FORTRAN type matmul for matrix multiplication. Instead of having nested do-loops to multiply two matrices A and B, one just writes C=matmul(A,B)
-
timing comparison of laborious nested version versus matmul method
-
linking in an external library, dgemv
-
example use of the allocatable array method in Fortran90
In the example we are going to multiply a 2-dimensional matrix,
hamiltonian by a column vector, psi: matrix by vector, this is what
is represented by the mv in dgemv. We are using double precision,
hence the d. If we were using integers it would be sgemv ; complex
would use c, or double complex would be z. This gives an idea of
the naming conventions.
To compile with pgf90 for example,
pgf90 matmul.f90 -lacml
or
pgf90 matmul.f90 /usr/pgi/linx86-64/5.2/lib llapack
Note the timings. You will no doubt see the manual version is several times slower than using matmul or dgemv; this may provide compelling evidence to swap over to at least this method in Fortran90 instead of the explicit method one has to construct when writing in F77.
Now since this is a matrix multiplication this is a vectorised process, so now try compiling with the -Mvect. Again you will see a speed-up.
One final thing. Let's profile the code: add the -Mprof=func option. This produces the tracefile, pgprof.out. Start the profiler, pgdbg pgprof.out. It now looks like that below. (Click the image for full size).
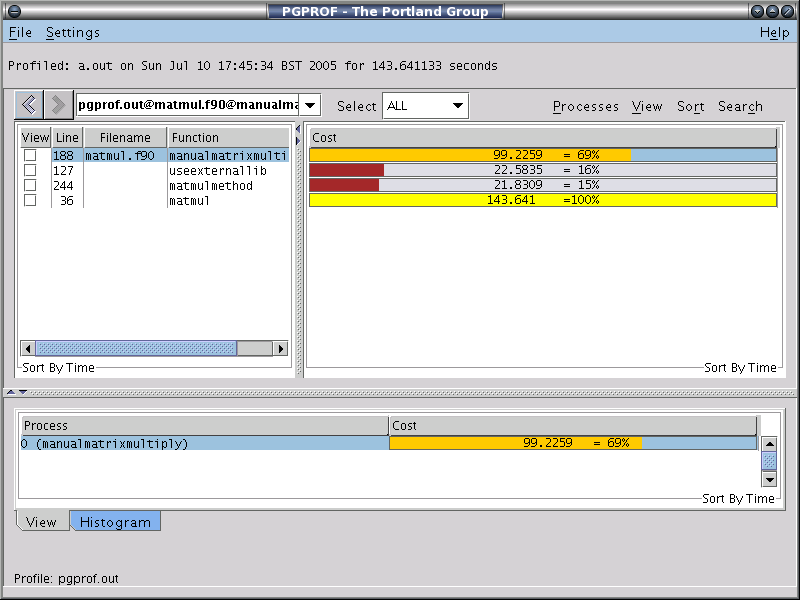
One can immediately see where it is spending the most time, in
the manual matrix multiplication routine, with 15% of the total
run time spent using matmul. Using a profiler like this is very
useful if you dont want to trawl through your code putting timing
flags in it, or indeed if you have just been given a binary (that
produces a tracefile) but no source code.